Prior 2D method (phase-based Eulerian) fails on a handheld-captured video with camera shake as it assumes stablized capture. Our method benefits from having a 3D representation and separates camear motion from scene motion.
We deploy our method on in-the-wild videos containing subtle motion, ranging from a sleeping baby breathing to celebrities attempting the Mannequin Challenge.
Abstract
Video motion magnification helps us visualize subtle, imperceptible motion. Prior methods, however, are only applicable to 2D videos. We present 3D motion magnification techniques that allow us to magnify subtle motions in dynamic scenes while supporting rendering from novel views. Our core idea is to represent the dynamic scene with time-varying radiance fields and leverage the Eulerian principle for motion magnification to analyze and amplify the embedding features from a fixed point over time. We study and validate the capability of 3D motion magnification for both implicit and explicit/hybrid NeRF models. We evaluate the effectiveness of our approaches on both synthetic and real-world dynamic scenes under various capture setups.
Approach
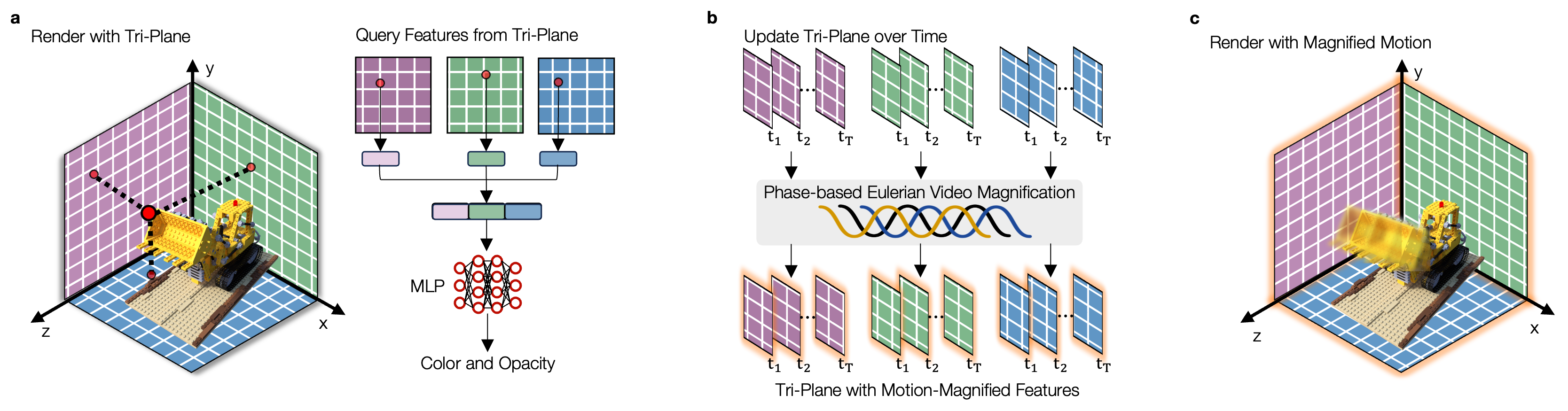
a. We adopt the tri-plane representation to associate each 3D point to its feature vector, which is fed to an MLP network to produce its color and opacity used for volume rendering. b. To represent the dynamic scene, we learn one feature tri-plane for each observed timestep. All timesteps share the same MLP which decodes the color and opacity, so features on the tri-plane are solely responsible for producing the subtle temporal variations. We first learn a tri-plane for a single timestep as the initialization, and then finetune the features for each remaining timestep. After learning the feature tri-planes, we can split them into three feature videos. These feature videos are separately processed by using phase-based video motion magnification, resulting in three motion-magnified feature videos. c. We recompose those three motion-magnified feature videos into a single motion-magnified tri-plane, which can be used for volume rendering without further modifications.
Single-camera results
We demonstrate successful 3D motion magnification on various real-world scenes with different subtle motions, scene compositions, and handheld video captures in the wild.
Multi-camera results
We deploy our method on multi-camera captures, including 8 synthetic scenes generated with Blender, and 2 real-world multi-camera scenes focused on human subjects.